
Behind the Latest Advance in IVF Treatment
A new study by Weill Cornell Medicine and NewYork-Presbyterian researchers uses artificial intelligence to improve the odds of a successful pregnancy.
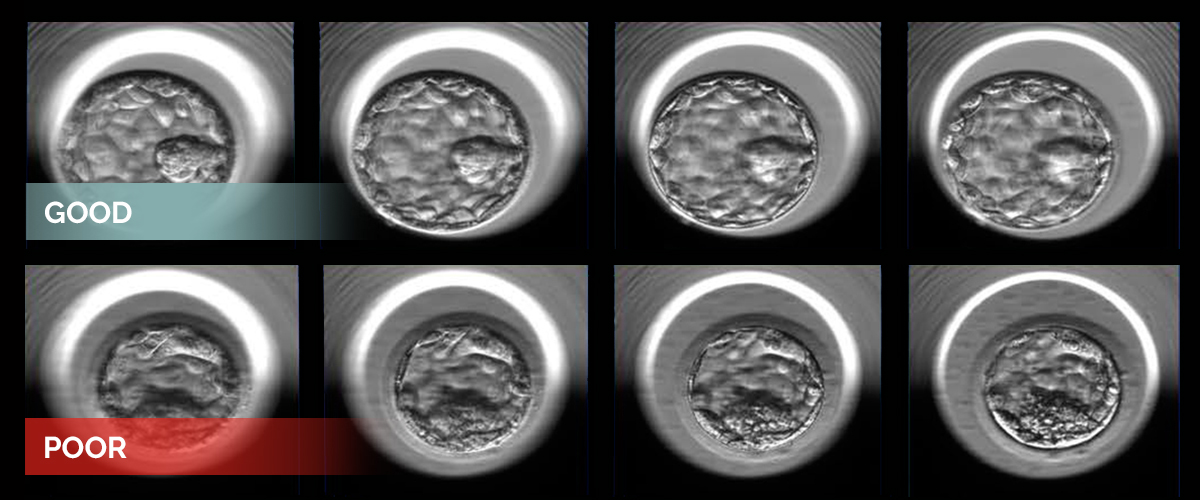
Two examples of human embryos at the blastocyst stage photographed at multiple focal depths. The embryos represent good (top) and poor quality (bottom) as designated by the embryologists’ grading system and additional statistical analysis.
Two examples of human embryos at the blastocyst stage photographed at multiple focal depths. The embryos represent good (top) and poor quality (bottom) as designated by the embryologists’ grading system and additional statistical analysis.
Each year, thousands of prospective parents turn to in vitro fertilization (IVF) to conceive. But the cost and effort involved in trying to get pregnant often diminish their hope.
A new approach, however, shows promise in making embryo selection more precise. Using artificial intelligence (AI), a team of investigators at Weill Cornell Medicine and NewYork-Presbyterian is now able to identify with a high degree of accuracy whether a 5-day-old in vitro fertilized human embryo has a high potential to progress to a successful pregnancy.
“By giving clinicians the ability to select the best embryo for implantation, the technique could reduce the number of in vitro fertilization cycles it takes to achieve a successful pregnancy, improve the success rate, and minimize the risk of multiple pregnancies,” says Dr. Zev Rosenwaks, director and physician-in-chief of the Ronald O. Perelman and Claudia Cohen Center for Reproductive Medicine at Weill Cornell Medicine and NewYork-Presbyterian and an obstetrician-gynecologist at NewYork-Presbyterian/Weill Cornell Medical Center.
“By introducing new technology into the field of IVF,” Dr. Rosenwaks adds, “we can automate and standardize a process that was very dependent on subjective human judgment.”
Infertility affects about 8 percent of women of child-bearing age, and while IVF has helped millions give birth, the average success rate in the United States is approximately 45 percent.
Because of these numbers, many women go through multiple rounds of treatment, driving the total cost upward of tens of thousands of dollars, not to mention the time involved and emotional stress.
“We are trying to tailor the process for the individual patient, because not every patient is the same. We want to leverage AI to personalize IVF to get the best results.”— Dr. Nikica Zaninovic
Choosing which embryos to implant falls to a fertility clinic’s embryologists, specialists who use a handful of methods — including microscopy and time-lapse monitoring of an embryo at the stage in which it consists of just 200 to 300 cells — to determine an embryo’s viability. Determining which embryo has the best chance of developing into a healthy pregnancy is a subjective process, and even experienced embryologists disagree.
Now, with the use of AI, embryo selection is poised to become far more precise.
“We wanted to develop an objective method that can be used to standardize and optimize the selection process to increase the success rates of IVF,” says Dr. Nikica Zaninovic, director of the Embryology Lab at Weill Cornell Medicine’s Center for Reproductive Medicine.
Dr. Zaninovic is a co-senior author of the team’s study, published in the April 2019 edition of NPJ Digital Medicine, in which they used 12,000 photos of human embryos taken 110 hours after fertilization to train an AI algorithm to discriminate between poor and good embryo quality.
To arrive at the designations, each embryo was first assigned a grade by embryologists who considered various aspects of the embryo’s appearance. Then the team, co-led by Dr. Pegah Khorasvi, postdoctoral associate, and Dr. Iman Hajirasouliha, assistant professor of physiology and biophysics and a member of the Englander Institute for Precision Medicine, both of Weill Cornell Medicine, performed a statistical analysis to determine the probability of an embryo becoming a successful pregnancy. Embryos were considered good quality if the chances were greater than 58 percent and poor quality if the chances were below 35 percent. After training and validation, the algorithm, called Stork, was able to classify the quality of a new set of images with 97 percent accuracy.
This type of AI is also called “deep learning,” an approach that is roughly modeled after the neural networks of the brain, which analyze information in increasing layers of complexity. As the computer is fed new information, its ability to recognize the desired patterns, whether they are the features of a healthy embryo or the cells of a lung cancer tumor, improves automatically. The size of the training data set is critically important to the success of the algorithm, with more data leading to better outcomes.
“This pioneering work gives us a window into how this field might look in the future.”— Dr. Zev Rosenwaks
“Our algorithm will help embryologists maximize the chances that their patients will have a single healthy pregnancy,” says Dr. Olivier Elemento, director of the Caryl and Israel Englander Institute for Precision Medicine at Weill Cornell Medicine and a co-senior author of the study. “The IVF procedure will remain the same, but we’ll be able to improve outcomes by harnessing the power of artificial intelligence.”
While Stork can select good quality embryos with a high degree of accuracy, previous studies show that only 80 percent of the pregnancy success rate is due to embryonic quality. Another factor is maternal age. The older a woman is, the less chance she has of a successful embryo implantation in the uterus. So fertility specialists often implant multiple embryos to try to maximize the chances of having one successful birth. The process, however, is imprecise and can result in multiple pregnancies, which carries its own risks, such as low birth weight, premature delivery, and maternal complications.
To help tackle this, the team developed another computational approach that can take into account maternal age and the quality of multiple embryos to determine the best combination to achieve a single live birth.
“We are trying to tailor the process for the individual patient, because not every patient is the same,” Dr. Zaninovic says of Stork. “We want to leverage AI to personalize IVF to get the best results.”
Although Stork is currently an investigative tool, meaning it’s not used on patients, the researchers are continuing to improve the algorithm, which may soon prove to be transformative.
“This pioneering work,” says Dr. Rosenwaks, “gives us a window into how this field might look in the future.”
A version of this story first appeared on Weill Cornell Medicine’s Newsroom.